A guide to building next-word prediction with AutoWord
Train a simple word prediction model with AutoWord
AutoWord
AutoWord is a basic deep-learning model that uses LSTM layers with word embeddings to predict the next word in a sequence. The model learns how to predict the next word by first constructing n-grams (bag of words) from the uploaded text file to train itself.Step 1: Upload a text file with training data
Keep in mind that the file needs to be in a TXT format. Project Gutenberg has several free books that are available in this format readily available for download.Project Gutenberg has several free books for download. link
Step 2: Set a number of epochs
The model will pick a random sample of data from the uploaded training file, create batches of it, and train over the specified number of epochs.You may have to find the right number of epochs based on the training data, but most of the time starting with 100 to 150 epochs may be sufficient to identify training loss and accuracy.Step 3: Create a new model or load from an existing checkpoint
If you're training a new file, create a new model. By providing a checkpoint name, you'll be able to save the model (checkpoint your work), following each successful run. AutoWord saves your model parameters, weights, and logs to the checkpoint following each run. For all subsequent runs, you'll be able to load and continue your training by providing the same checkpoint name.Step 4: Checkpoint name
Provide an unique checkpoint name that you can remember easily to checkpoint your work following each run.Keep checkpoint names unique and easy to remember. Ex: "timemachine-cp-1"
Step 5: Begin Training
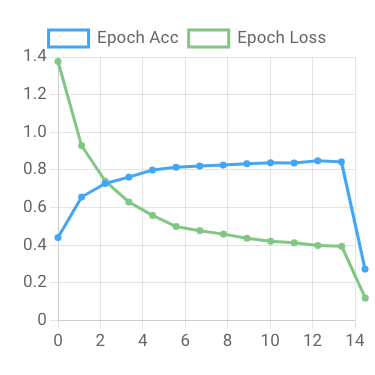
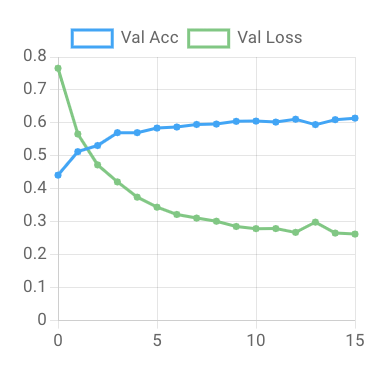
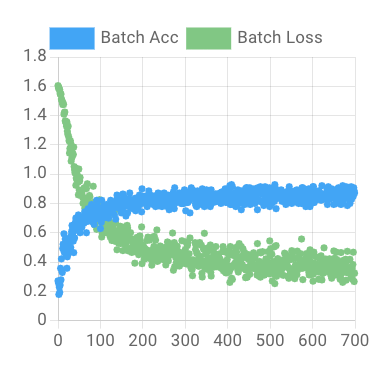
Start Training! Model training may take a minute or two to begin. Once the model training starts, you'll see graphs indicating training progress.